Volledige anonimiteit bestaat niet
Overheden, onderzoeksinstellingen of bedrijven geven vaak om allerlei redenen 'geanonimiseerde' data vrij over personen. Helaas blijkt het in veel gevallen nog mogelijk om de personen achter de data te identificeren.
In PC-Active 311 van april schreef ik een artikel over de moeilijkheid om echt geanonimiseerde datasets aan te maken. Het artikel is nu ook op de website gepubliceerd: Volledige anonimiteit bestaat niet.
Bruikbaar of anoniem, nooit beide
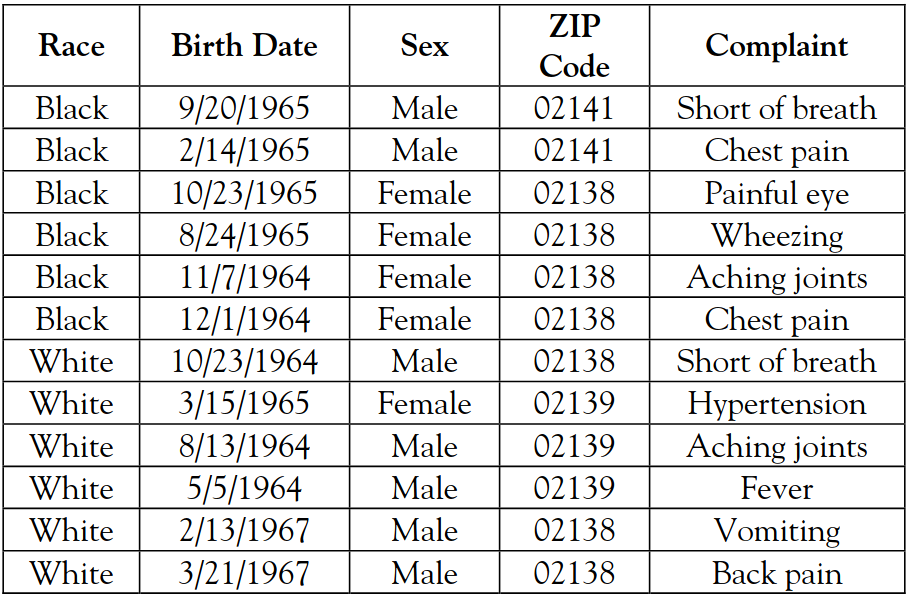
Een veel geciteerd artikel is dat van professor Paul Ohm van de University of Colorado Law School: Broken Promises of Privacy: Responding to the Surprising Failure of Anonymization (2010). Daarin argumenteert hij dat privacywetten niet volstaan om re-identificatie van personen in 'geanonimiseerde' datasets tegen te gaan. Privacywetten beperken zich immers tot gegevens die jou persoonlijk identificeren.
In deze tijd van grootschalige databases en grote computerkracht is het echter kinderspel om gigantisch veel gegevens te combineren, te vergelijken en te correleren, waardoor je uit een combinatie van schijnbaar anonieme gegevens die volledig aan de privacywetten voldoen de identiteit van iemand kunt achterhalen.
Ohms voorstel was om niet meer toe te laten zulke grote databases in zijn geheel te analyseren, maar ze interactief te maken of alleen gemiddeldes over verschillende personen als resultaat terug te geven. Dat beperkt natuurlijk de bruikbaarheid van de gegevens, maar dat is juist zijn punt: gegevens zijn ofwel bruikbaar ofwel perfect anoniem, maar nooit beide. Geen enkele bruikbare database kan perfect anoniem zijn en hoe bruikbaarder de data gemaakt worden, hoe minder privacy de betreffende personen hebben.
Hoe dan wel anonimiseren?
In het artikel bespreek ik diverse studies waaruit blijkt dat elke anonimisering van individuele gegevens gedoemd is om gedeanonimiseerd te worden. Enkele aanpakken die beter werken, zijn:
Gegevens van verschillende personen samenvoegen en alleen deze geaggregeerde data in de dataset bijhouden.
Privacygevoelige gegevens van ruis voorzien en de gegevens van meerdere personen bij elkaar optellen om statistieken te berekenen, zodat personen niet meer op individueel niveau te identificeren zijn. Dit heet differentiële privacy.
Een neuraal netwerk trainen op identificeerbare gegevens en daarmee een synthetische dataset genereren die statistisch identiek is aan de originele dataset, maar op geen enkele manier meer tot individuele personen terug te leiden is.
Kortom, anonimiteit is niet eenvoudig te bereiken.