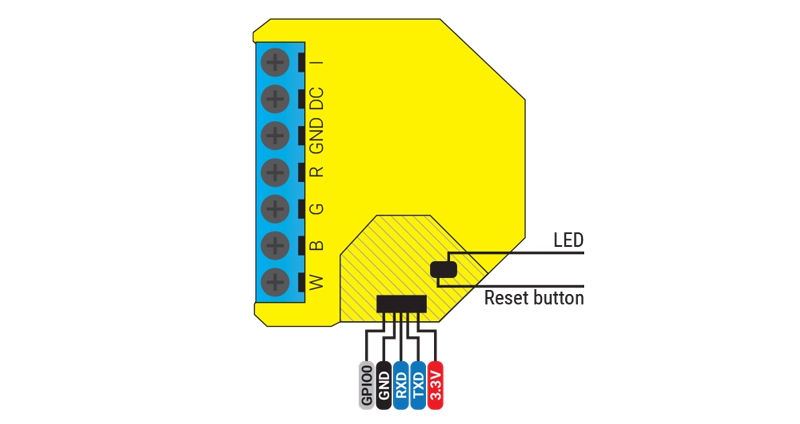
Using the M5Core2 for ESP32 development
A Wi-Fi enabled microcontroller such as the ESP32 or ESP8266 has a lot of applications, but if you use a development board, the result doesn't really look appealing in your living room, unless you spend some effort in creating your own case.
Enter M5Stack, a young Chinese company that offers a lot of ESP32-based products that don't look like development boards but like finished products. I first encountered them two years ago when I discovered their M5Stack Core BASIC Kit: a modular, stackable, ESP32 board with a 2 inch LCD screen, all in a package that doesn't look bad in your living room. I bought one and turned it into a dashboard for my MQTT-based home automation system: it could read the temperature and humidity of various sensors in my home by subscribing to the corresponding MQTT messages and showing them on the screen.

Now M5Stack has sent me their newest product: the M5Core2. It has more RAM, a touch screen, a real-time clock and even a microphone. This looks like an even better dashboard for my home automation system, adding a lot of possibilities.
Although from time to time you still bump into Chinese data sheets or code comments, I noticed that M5Stack's documentation and code has improved considerably since I last checked it for the first generation of this product. For the new M5Core2 there's:
the Arduino example code, including the code that is put into the device in the factory;
the documentation, including pin maps, schematics and data sheets.
I'm definitely going to experiment with this device and see how I can integrate this in my home automation system. I can reuse a lot of existing Arduino libraries, and together with the M5Core2 Arduino library it should be fairly straightforward to come up with a prototype.
Some specifications:
ESP32-D0WD-V3 |
240 MHz dual core, 600 DMIPS, 520 KB SRAM, Wi-Fi, dual mode Bluetooth |
Flash |
16 MB |
PSRAM |
8 MB |
Input Voltage |
5 V @ 500 mA |
Interface |
TypeC x 1, GROVE (I²C + I/O + UART) x 1 |
IPS LCD Screen |
2.0"@320*240 ILI9342C |
Touch Screen |
FT6336U |
Speaker |
1W-0928 |
LED |
Green power indicator light |
Button |
Power button, RST button, Virtual screen button x 3 |
Vibration reminder |
Vibration motor |
MIC |
SPM1423 |
I2S Power Amplifier |
NS4168 |
6-axis IMU |
MPU6886 |
RTC |
BM8563 |
PMU |
AXP192 |
USB Chip |
CP2104 |
DC-DC Boost |
SY7088 |
TF card slot |
16 GB max |
Lithium Battery |
390m Ah @ 3.7 V |
Antenna |
2.4 GHz 3D antenna |
Operating temperature |
0°C to 40°C |
Net Weight |
52 g |
Gross Weight |
70 g |
Product Size |
54 mm x 54 mm x 16 mm |
Package Size |
75 mm x 60 mm x 20 mm |
Case Material |
Plastic |